

Data Engineering
Data Engineering
We offer all types of data engineering services to help you transform your raw data into valuable insights. This includes, for example, building automated data pipelines to extract and clean data, deliver it securely into your data lake, catalog it, transform it and/or load it into your data warehouse.
Data Ingestion
Ingesting data involves collecting, preparing and moving data from various sources into AWS services such as S3, Redshift, Kinesis or DynamoDB for storage, processing and analysis. We focus on selecting and implementing the correct types of data ingestion processes to move diverse data types from a range of different sources into a unified data ecosystem for scalable cloud-based operations.
Data Pipelines: ETL or ELT
ETL pipelines in AWS extract data, transform it with AWS Glue and load it into Amazon Redshift. On the other hand, ELT pipelines load raw data into Amazon S3 or Redshift before transforming it for analysis.
Data Pre-processing Jobs
Pre-processing or transformation jobs involve cleaning and converting raw data into a format suitable for analysis using tools like AWS Glue and PySpark. Data quality evaluation employs AWS Glue DataBrew and Glue DQDL rules to profile, clean and validate data. This ensures accuracy and usability in downstream applications.
Data Lake as Code
A data lake as code in AWS uses Infrastructure as Code (IaC) tools like the AWS Cloud Development Kit for automated and version-controlled deployment of data storage. This enables efficient management of storage, cataloging and analysis of large volumes of structured and unstructured data.
Data Warehousing and Data Marts
In AWS data warehousing uses columnar database engines such as Amazon Redshift to store and analyse large volumes of structured data in order to create a centralised repository for business intelligence. Data marts focus on specific business areas for quicker, targeted analysis.
Data cataloging
Cataloging and classification of data uses tools such as AWS Glue Data Catalog, Amazon Lake Formation and data tagging for schema version control, data access governance.
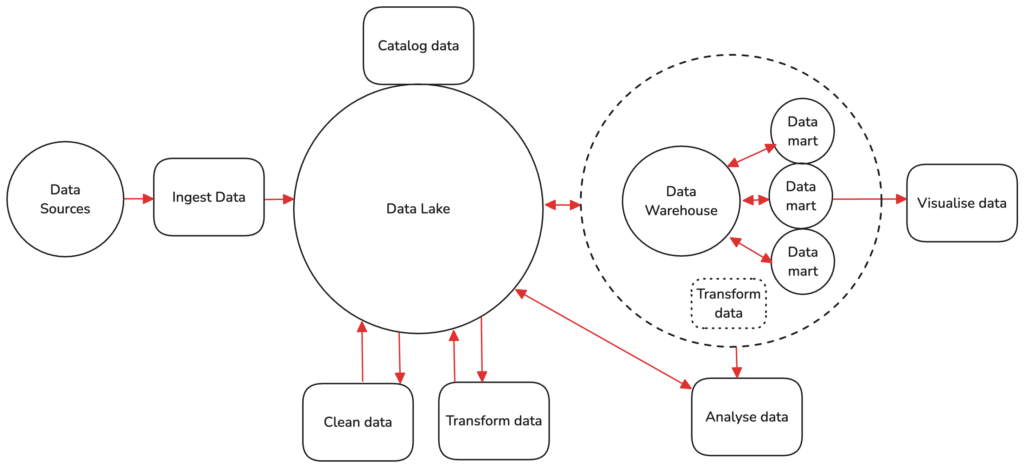
Demo
All areas of the modern AWS data architecture that we cover. Elements may vary.

Get In Touch
Ready to solve your data challenges? Contact us to find out more about our services and pricing